
Yapay zeka çalışmalarına hız kesmeden devam eden Meta, görsel alandaki başarısının ardından şimdi de ses alanında çığır açacak yeni modeli SAM Audio'yu tanıttı. Segment Anything Model (SAM) ailesinin yeni üyesi, ses işleme yetenekleriyle dikkat çekiyor.
Meta'dan Ses İşleme Alanında Devrim: SAM Audio
SAM Audio, karmaşık ses ortamlarından istenilen sesleri ayıklama konusunda benzersiz bir yetenek sunuyor. İnsanların ses algısına benzer bir yaklaşım sergileyen bu yeni model, çoklu girdi seçenekleriyle ses ayrıştırma süreçlerini kolaylaştırıyor ve daha erişilebilir hale getiriyor.
Geleneksel ses düzenleme araçlarından farklı olarak, SAM Audio kullanıcılara metin komutları, görsel işaretlemeler veya zaman aralıkları gibi doğal etkileşim yöntemleri sunarak pratik bir kullanım deneyimi sağlıyor. Örneğin, bir konser kaydındaki gitar sesini işaretleyerek izole etmek veya bir podcast'teki istenmeyen sesleri metin komutuyla temizlemek mümkün hale geliyor.
Meta, SAM Audio'nun çok modlu yapay zeka modellemesi alanında bir ilk olduğunu belirtiyor. Modelin temelini oluşturan Perception Encoder Audiovisual (PE-AV), SAM Audio'nun yüksek performansının arkasındaki kilit teknik bileşen olarak öne çıkıyor.

SAM Audio'nun Teknik Özellikleri ve Potansiyel Kullanım Alanları
Daha önce açık kaynak olarak yayınlanan PE-AV modelinin geliştirilmiş versiyonu, görsel ve işitsel verileri eş zamanlı olarak işleyerek yüksek doğrulukta ses ayrıştırması yapabiliyor. Bu sayede, ekranda görünen konuşmacılar veya enstrümanlar gibi görsel kaynaklar kolayca ayrıştırılabilirken, sahne içerisindeki diğer ses olayları da doğru bir şekilde tespit edilebiliyor.
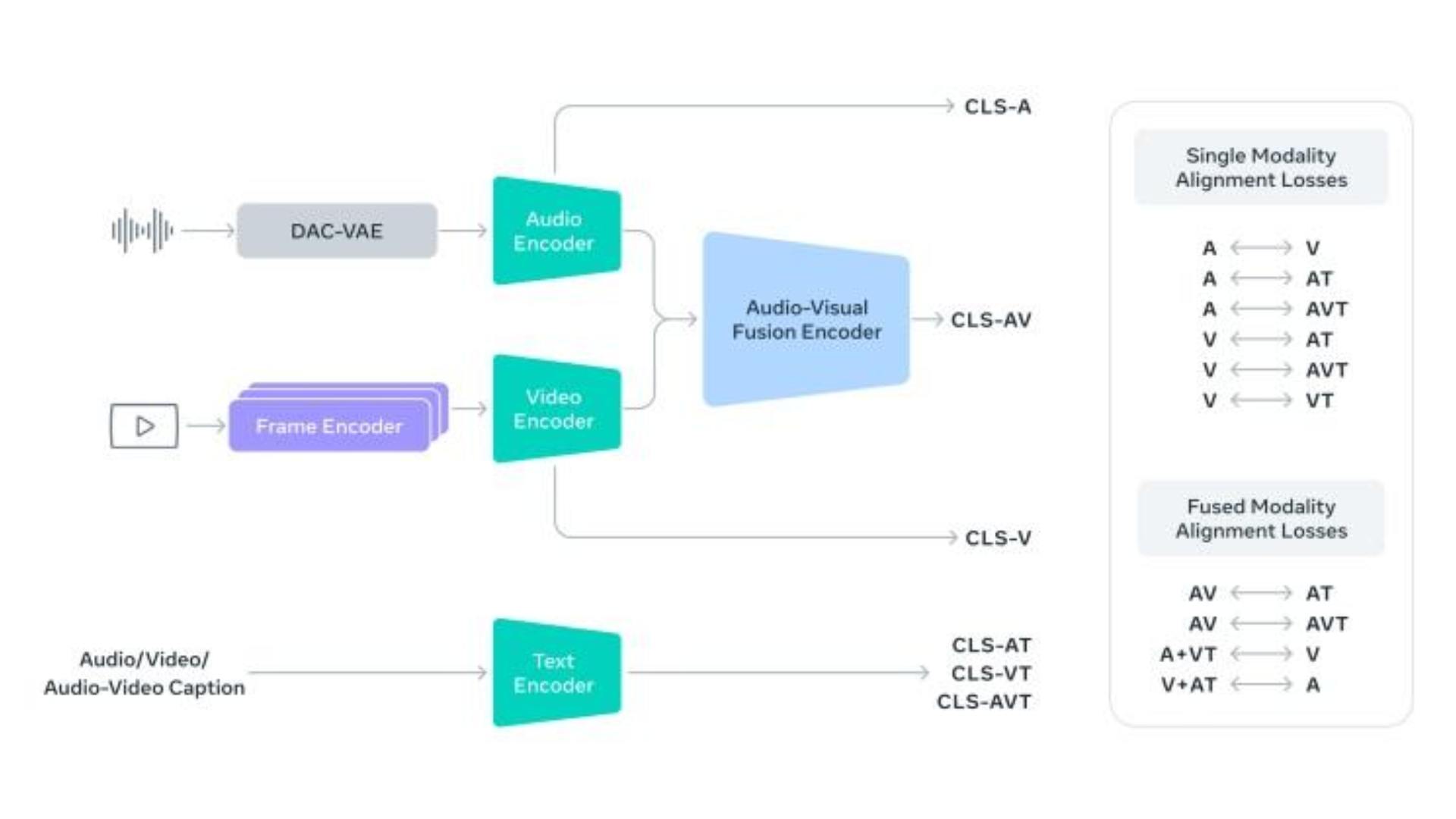
SAM Audio, kullanıcılarına metin tabanlı, görsel tabanlı ve zaman dilimi tabanlı olmak üzere üç farklı ses segmentasyonu yöntemi sunuyor. Kullanıcılar, metin komutlarıyla ("köpek havlaması", "vokal" gibi) belirli sesleri ayırabilir, videodaki nesnelere tıklayarak sesi izole edebilir veya podcast kaydındaki istenmeyen sesleri belirli zaman aralıklarında filtreleyebilirler.
Performans, Güvenlik ve Erişilebilirlik
SAM Audio'nun mimarisi, akış eşleştirme difüzyon dönüştürücüsü üzerine inşa edilmiş bir üretken modelleme çerçevesi kullanır. Bu yapı, ses karışımını ve kullanıcı girdilerini ortak bir alana kodlayarak istenen ve kalan ses parçalarını oluşturur. Modelin eğitim verileri, konuşma, müzik ve çeşitli ses olaylarını içeren gerçek ve sentetik karışımlardan oluşmaktadır. Gelişmiş veri sentezi sayesinde modelin gerçek dünya koşullarında yüksek performans göstermesi hedefleniyor.
Performans testlerinde SAM Audio, genel ses ayrıştırma konusunda mevcut modelleri geride bırakırken, özel alanlardaki modellerle de rekabet edebiliyor. Farklı girdi yöntemlerinin bir arada kullanılması, daha da iyi sonuçlar elde edilmesini sağlıyor. Model, 500 milyon ile 3 milyar parametre arasında ölçeklenebilir ve gerçek zamanlıya yakın bir hızda (RTF ≈ 0.7) çalışabiliyor.
Modelin bazı sınırlamaları da bulunuyor. Örneğin, sesin kendisi doğrudan bir girdi olarak kullanılamıyor ve tamamen girdi olmadan ayrıştırma yapmak mümkün değil. Ayrıca, birbirine çok benzeyen sesleri ayırmak hala zorlayıcı olabiliyor. SAM Audio'nun yetenekleri, beraberinde bazı güvenlik endişelerini de getiriyor. Modelin kötüye kullanılması senaryoları arasında, halka açık kayıtlardaki konuşmaları izole ederek dinlemek gibi durumlar yer alabilir.
Modeli buradan deneyebilir veya buradan indirebilirsiniz.
Kaynak: (Donanım Haber)

Intel Arc B390 iGPU Performansı: Mobil Grafikte Yeni Dönem

MSI'dan Oyunculara Yönelik Yeni Nesil QD-OLED Monitörler Duyuruldu

DeepSeek'in Yeni Mimarisi AI Eğitim Maliyetlerini Düşürecek

BYD Yuan Max: Yeni Elektrikli SUV Test Sürüşlerinde Görüntülendi

Luxeed V9: Kask Hava Yastığına Sahip İlk Seri Üretim Otomobil Geliyor

İlk yorumu sen yap! Düşüncelerini bizimle paylaş.